|
|
|
|
|
|
|
|
|
|
|
| Partitioned Memory
Parallel Programming Library (PMLIB) |
|
|
|
| Based on BSP-RAMP:
Partitioned Memory Parallel Programming Framework |
|
|
|
| |
|
|
Prof.
Subodh Kumar |
Prof.
Sorav Bansal |
|
|
|
|
|
|
| Tarun Beri |
|
|
|
| Indian Institute of
Technology, Delhi |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Square Matrix Multiplication |
|
|
|
|
|
|
| Experimental
Configuration |
|
14 |
|
| Four 64-bit Ubuntu
Linux 8.04.2 Eight Core Machines [Intel Xeon CPU E5450 3.00 GHz with 16 GB
physical memory]; |
|
5 |
|
| Two machines have
one Tesla C1060 GPU Card each |
|
9 |
|
| Watch Dog/Kernel
Execution Timeout Disabled; mpiexec with 4 processes on different machines; |
|
|
|
| CUDA Version 3.1; OpenMPI Version 1.78;
OpenMP Version 3.0; gcc Version 4.2.4 |
|
|
|
| Equal task
partitioning among all processing elements |
|
|
|
|
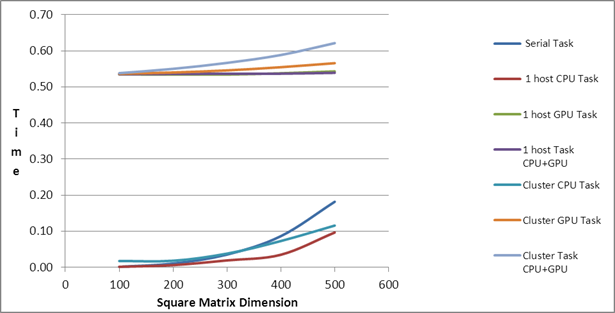
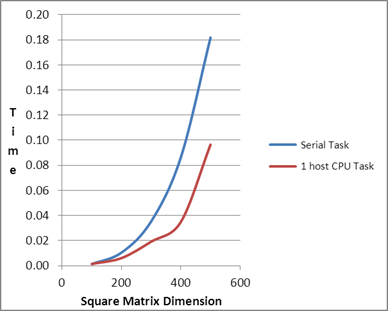
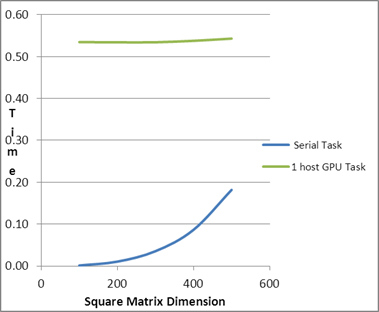
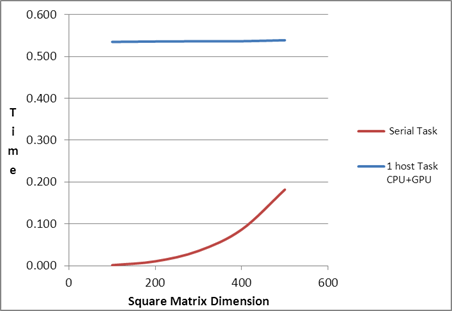
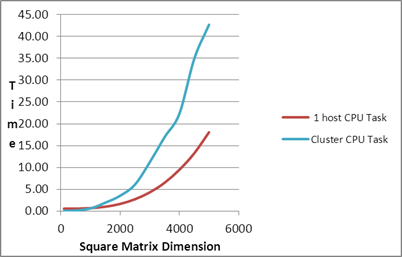
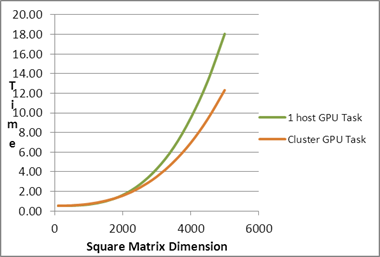
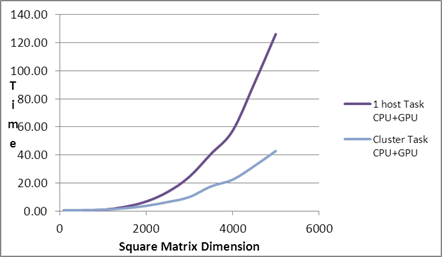
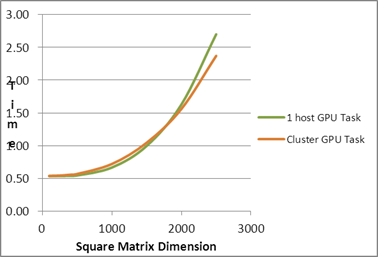
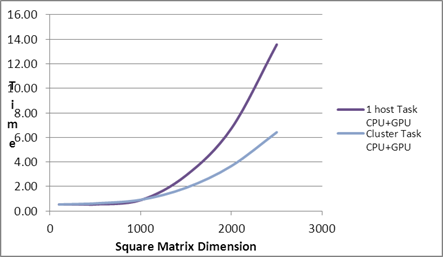
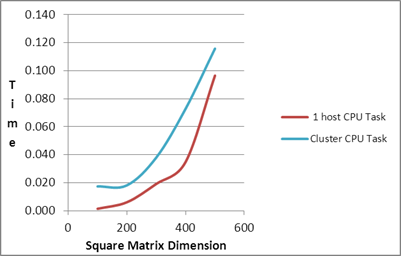
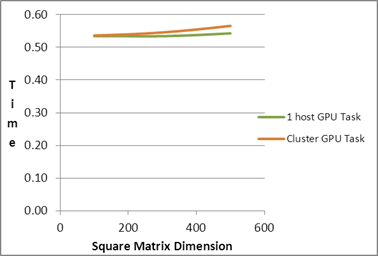
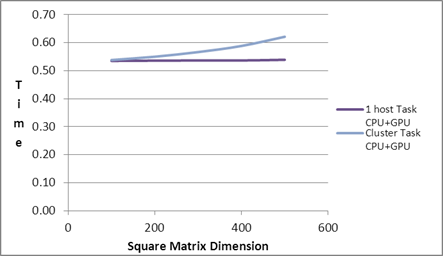
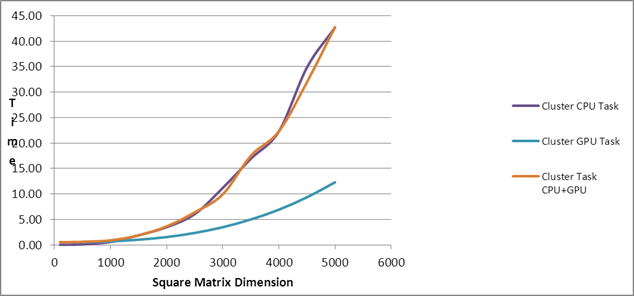
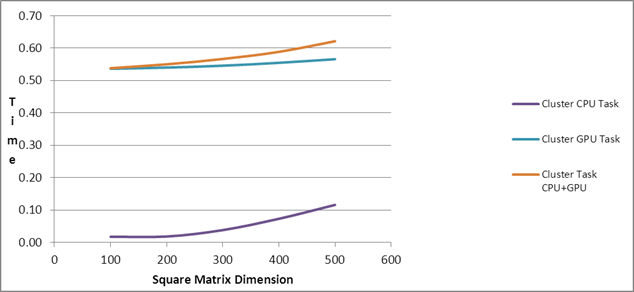
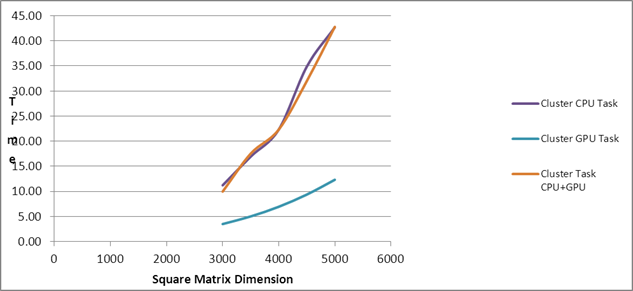
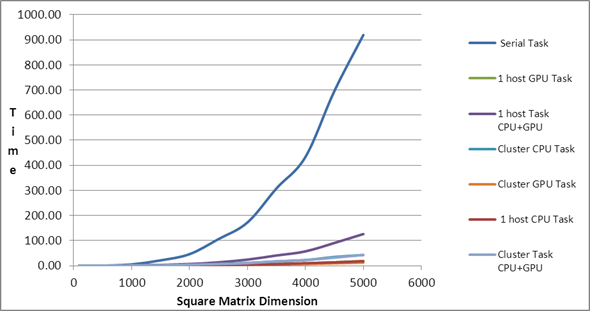
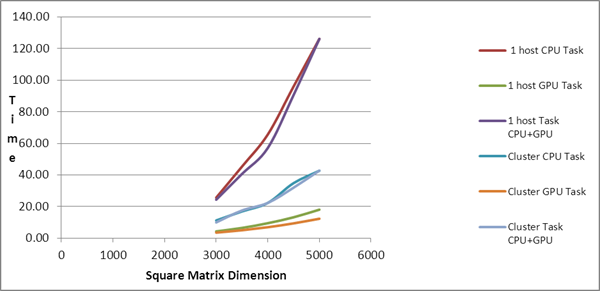
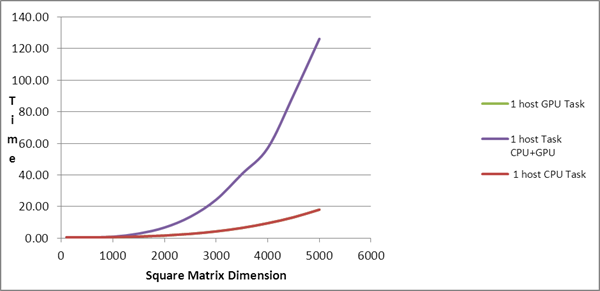
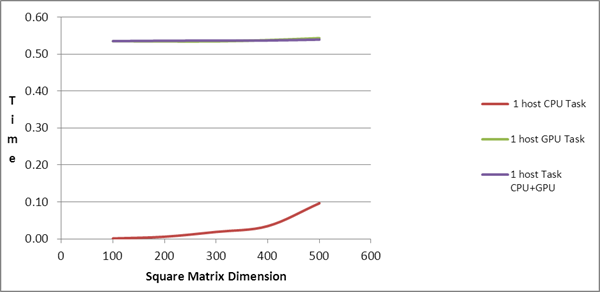
| Square Matrix Dimension |
Matrix
Multiplication Time (in seconds) |
|
| |
Serial Task |
1 host CPU Task |
1 host GPU Task |
1 host Task
CPU+GPU |
Cluster CPU Task |
Cluster GPU Task |
Cluster Task
CPU+GPU |
|
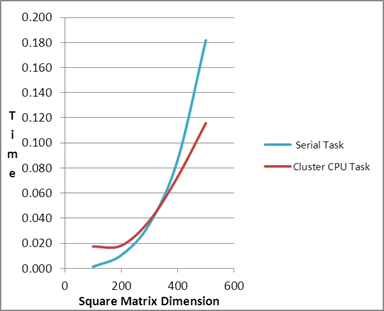
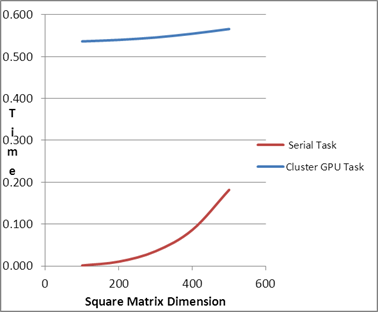
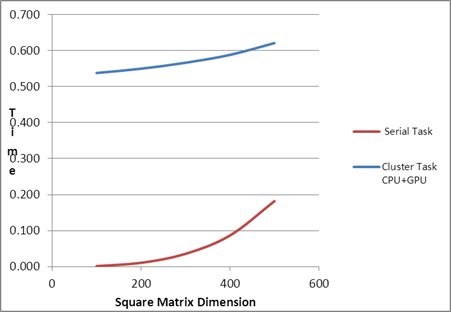
| 100 |
0.001 |
0.001 |
0.53 |
0.54 |
0.02 |
0.54 |
0.54 |
|
| 200 |
0.01 |
0.01 |
0.53 |
0.54 |
0.02 |
0.54 |
0.55 |
|
| 300 |
0.04 |
0.02 |
0.53 |
0.54 |
0.04 |
0.55 |
0.57 |
|
| 400 |
0.09 |
0.03 |
0.54 |
0.54 |
0.07 |
0.55 |
0.59 |
|
| 500 |
0.18 |
0.10 |
0.54 |
0.54 |
0.12 |
0.57 |
0.62 |
|
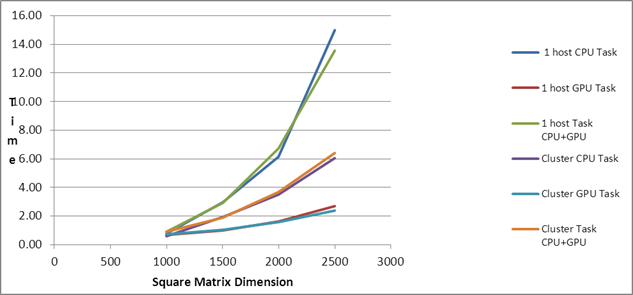
| 1000 |
5.22 |
0.77 |
0.66 |
0.89 |
0.60 |
0.72 |
0.92 |
|
| 1500 |
21.34 |
2.98 |
0.99 |
2.90 |
1.91 |
1.04 |
1.90 |
|
| 2000 |
45.91 |
6.15 |
1.63 |
6.73 |
3.50 |
1.56 |
3.67 |
|
| 2500 |
106.01 |
14.99 |
2.70 |
13.57 |
6.06 |
2.37 |
6.42 |
|
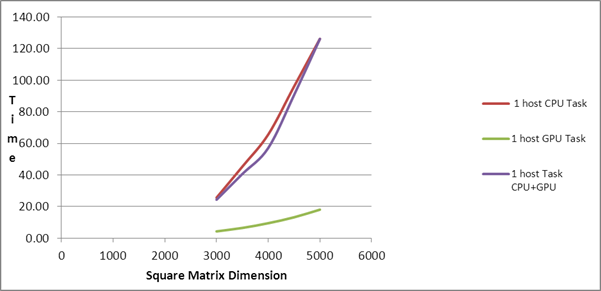
| 3000 |
172.24 |
25.61 |
4.29 |
24.35 |
11.20 |
3.50 |
9.95 |
|
| 3500 |
307.82 |
45.33 |
6.48 |
40.64 |
16.93 |
5.01 |
17.52 |
|
| 4000 |
433.02 |
65.62 |
9.46 |
57.08 |
22.31 |
6.94 |
22.31 |
|
| 4500 |
695.93 |
96.05 |
13.22 |
90.62 |
34.85 |
9.36 |
31.97 |
|
| 5000 |
919.17 |
126.21 |
18.05 |
126.20 |
42.70 |
12.32 |
42.78 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Comparison of
Serial and PMLIB Tasks |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Comparison of PMLIB
Tasks |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
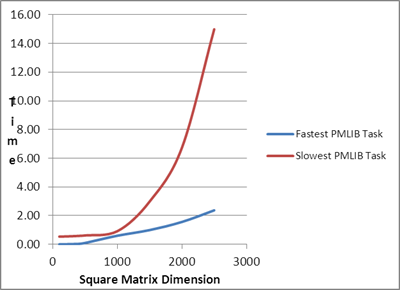
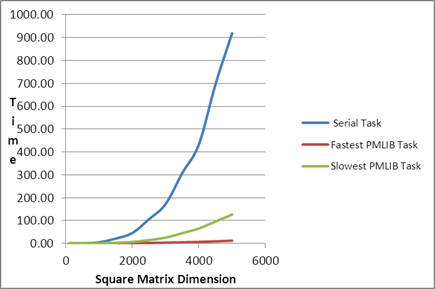
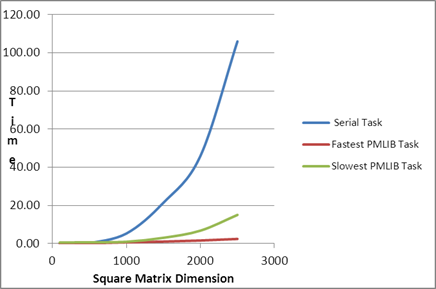
| Comparison of
Serial Task, Fastest PMLIB Task and Slowest PMLIB Task |
|
| Square Matrix Dimension |
Matrix
Multiplication Time (in seconds) |
|
| |
Serial Task |
1 host CPU Task |
1 host GPU Task |
1 host Task
CPU+GPU |
Cluster CPU Task |
Cluster GPU Task |
Cluster Task
CPU+GPU |
Fastest PMLIB Task |
Slowest PMLIB Task |
|
| 100 |
0.001 |
0.001 |
0.53 |
0.54 |
0.02 |
0.54 |
0.54 |
0.001 |
0.54 |
|
| 200 |
0.01 |
0.01 |
0.53 |
0.54 |
0.02 |
0.54 |
0.55 |
0.01 |
0.55 |
|
| 300 |
0.04 |
0.02 |
0.53 |
0.54 |
0.04 |
0.55 |
0.57 |
0.02 |
0.57 |
|
| 400 |
0.09 |
0.03 |
0.54 |
0.54 |
0.07 |
0.55 |
0.59 |
0.03 |
0.59 |
|
| 500 |
0.18 |
0.10 |
0.54 |
0.54 |
0.12 |
0.57 |
0.62 |
0.10 |
0.62 |
|
| 1000 |
5.22 |
0.77 |
0.66 |
0.89 |
0.60 |
0.72 |
0.92 |
0.60 |
0.92 |
|
| 1500 |
21.34 |
2.98 |
0.99 |
2.90 |
1.91 |
1.04 |
1.90 |
0.99 |
2.98 |
|
| 2000 |
45.91 |
6.15 |
1.63 |
6.73 |
3.50 |
1.56 |
3.67 |
1.56 |
6.73 |
|
| 2500 |
106.01 |
14.99 |
2.70 |
13.57 |
6.06 |
2.37 |
6.42 |
2.37 |
14.99 |
|
| 3000 |
172.24 |
25.61 |
4.29 |
24.35 |
11.20 |
3.50 |
9.95 |
3.50 |
25.61 |
|
| 3500 |
307.82 |
45.33 |
6.48 |
40.64 |
16.93 |
5.01 |
17.52 |
5.01 |
45.33 |
|
| 4000 |
433.02 |
65.62 |
9.46 |
57.08 |
22.31 |
6.94 |
22.31 |
6.94 |
65.62 |
|
| 4500 |
695.93 |
96.05 |
13.22 |
90.62 |
34.85 |
9.36 |
31.97 |
9.36 |
96.05 |
|
| 5000 |
919.17 |
126.21 |
18.05 |
126.20 |
42.70 |
12.32 |
42.78 |
12.32 |
126.21 |
|
|
|
|
|
|
|
|
|
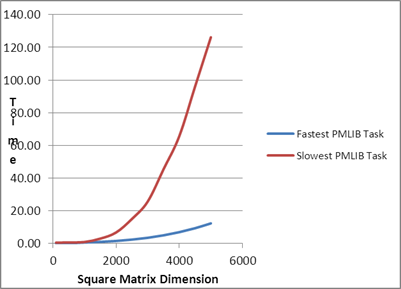
Fastest LPC Task |
Slowest LPC Task |
|
|
|
|
|
|
|
|
|
|
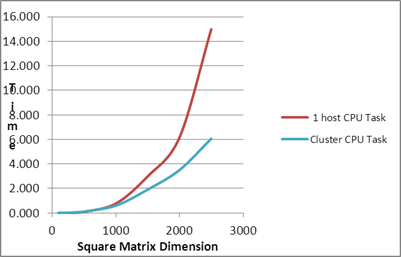
| Square Matrix Dimension |
Matrix
Multiplication Time (in seconds) |
% Speedup of PMLIB Task over Serial Task |
|
|
|
|
|
| |
Serial Task |
Fastest PMLIB Task |
Slowest PMLIB Task |
Fastest PMLIB Task |
Slowest PMLIB Task |
|
|
|
| 100 |
0.001 |
0.001 |
0.54 |
94.36 |
0.24 |
|
| 200 |
0.01 |
0.01 |
0.55 |
172.32 |
1.90 |
|
| 300 |
0.04 |
0.02 |
0.57 |
184.28 |
6.23 |
|
| 400 |
0.09 |
0.03 |
0.59 |
247.63 |
14.67 |
|
Max PMLIB Speedup over Serial Task |
|
| 500 |
0.18 |
0.10 |
0.62 |
188.35 |
29.25 |
|
74.64x |
|
| 1000 |
5.22 |
0.60 |
0.92 |
868.15 |
569.52 |
|
| 1500 |
21.34 |
0.99 |
2.98 |
2147.04 |
715.60 |
|
| 2000 |
45.91 |
1.56 |
6.73 |
2942.27 |
682.07 |
|
| 2500 |
106.01 |
2.37 |
14.99 |
4469.61 |
707.25 |
|
| 3000 |
172.24 |
3.50 |
25.61 |
4927.79 |
672.46 |
|
| 3500 |
307.82 |
5.01 |
45.33 |
6142.32 |
678.99 |
|
| 4000 |
433.02 |
6.94 |
65.62 |
6242.61 |
659.92 |
|
| 4500 |
695.93 |
9.36 |
96.05 |
7432.48 |
724.55 |
|
| 5000 |
919.17 |
12.32 |
126.21 |
7463.53 |
728.27 |
|
|
|
PMLIB Tasks
slower than Serial Task |
PMLIB Tasks
faster than Serial Task |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|