2 Threads
2.1 Stackless Coroutine
MergeRequest
I’ve added few more code in origin/coroutine branch. Please merge it with your master branch
user@host:~/hohlabs$ git pull
user@host:~/hohlabs$ git merge origin/coroutineAim
In this part, we’ll learn about “asymmetric-stackless coroutines” while enhancing our kernel to make it responsive to key presses while long computation task is running.
- You shall implement the long computation task as a stackless coroutine using the given APIs and add a new menu item/builtin command for the same.
- On key press, the status bar shall be updated with ‘the number of keys pressed so far’ while this long computation task is running(not after it finishes).
- If we select older menu item, shell still take seconds to respond to update status bar. If we select new menu item, shell will be updating status bar, while the computation is running.. Result of both the menu items should be same.
- Atmost one pending long computation task at any point in time.
- Only convert one long computation task to coroutine form(If your shell supports multiple long computation task).
Information
Coroutines are a generalization of coroutines which allows explicit suspend and resume operations(yield and call). Coroutines can be used for nonpremptive multitasking(fibers), event loop, and light weight pipes(producer consumer problem).
Definition of coroutine from Coroutines: A Programming Methodology, a Language Design and an Implementation(1980):
For the purposes of this thesis, the following will be regarded as
the fundamental characteristics of a coroutine:
(1) the values of data local to a coroutine persist between
successive occasions on which controls enters it (that is, between
successive calls), and
(2) the execution of a coroutine is suspended as control leaves it,
only to carry on where it left off when control re-enters the
coroutine at some later stage.Classification of coroutines from Revisiting coroutines(2009):
- Symmetric vs Asymmetric : whether coroutine can yield to other coroutines or it’s parent only.
- First class vs Constrained : First class object or not.
- Stackfulness vs Non-stackfulness: Can we call coroutine within another coroutine?
There is a proposal to support coroutines in C++. (Several languages like: C#, Perl, Python, Haskell, Erlang, Scheme, Factor supports coroutines.)
See Simon Thatham’s coroutine implementation or boost coroutine’s Introduction & Motivation or Protothreads for more details.
Slides: Coroutines and Fibers
Since we don’t have language support yet, Let’s first build a coroutine library first.
- We’ll store values of “data local to a coroutine between successive calls” in a structure, say f_t.
- We’ll store value of program counter from where the execution has to carry on in another structure - coroutine_t.
- coroutine_init() will initalize the program counter inside coroutine_t structure to zero.
- h_begin() will check the value of program counter, and if non-zero, will jump to that value.
- h_yield() stores the PC of next instruction to be executed in coroutine_t structure, and returns.
- h_end() resets the value of PC to zero.
You’ll help me in implementing the long computation as a coroutine.
Define
You need to define the following structures in labs/coroutine.h
// state for your coroutine implementation:
struct f_t{
};You also need to define the following functions in labs/coroutine.cc
shell_step_coroutine(shellstate_t&, coroutine_t&, f_t&);You also need to enhance your shell implementation in labs/shell.h
update shellstate_t and renderstate_t structure: i
for handling coroutine state, and
new menu item for long computation task in coroutine formYou also need to enhance your shell implementation in labs/shell.cc
new menu item for long computation taskUsage
core_loop_step():
if user has pressed key, get the key and do:
shell_update(ro: key, rw: shell_state);
// execute shell for one time slot to do some computation, if required.
shell_step(rw: shell_state);
// execute shell for one time slot to do some computation based on coroutine, if required.
shell_step_coroutine(rw: shell_state, f_coro, f_locals);
// shellstate -> renderstate: compute render state from shell state
shell_render(ro: shell_state, wo: render_state);
if not render_eq(last renderstate and new renderstate):
render(ro: render_state, wo: vga text buffer);Given
Following functions are defined in util/coroutine.h:
coroutine_t : internal data structure to save the state of coroutine (where to continue)
coroutine_reset() : initialize/reset coroutine_t
h_begin() : begin coroutine ( jump to saved state )
h_yield() : yield ( save the state, and return)
h_end() : end ( infinitely call yield )Example usage of coroutines
//
// state of function f to be preserved across multiple calls.
//
struct f_t{
int i;
int j;
};
//
// first time you call f(), it'll
// execute h_yield with value 1. (i=1 and j=1 at this point)
//
// next time you resume/call it, it'll continue execution from this point,
// and calls h_yield with value 2 (i=1 and j=2 at this point)
//
// In short, each time you resume/call f(), it'll return
//
// 1*1, 1*2, 1*3
// 2*1, 2*2, 2*3
// 3*1, 3*2, 3*3
//
//
void f(coroutine_t* pf_coro,f_t* pf_locals,int* pret,bool* pdone){
coroutine_t& f_coro = *pf_coro; // boilerplate: to ease the transition from existing code
int& ret = *pret;
bool& done = *pdone;
int& i = pf_locals->i;
int& j = pf_locals->j;
h_begin(f_coro);
for(i=1;i<=3;i++){
for(j=1;j<=3;j++){
ret=i*j; done=false; h_yield(f_coro); // yield (i*j, false)
}
}
ret=0; done=true; h_end(f_coro); // yield (0,true)
}
// How to use use f()?
coroutine_t f_coro;
coroutine_reset(f_coro);
f_t f_locals;
f(f_coro,f_locals,shell.f_ret,shell.f_done); //post cond: f_ret=1*1 f_done=false
f(f_coro,f_locals,shell.f_ret,shell.f_done); //post cond: f_ret=1*2 f_done=false
f(f_coro,f_locals,shell.f_ret,shell.f_done); //post cond: f_ret=1*3 f_done=false
f(f_coro,f_locals,shell.f_ret,shell.f_done); //post cond: f_ret=2*1 f_done=false
f(f_coro,f_locals,shell.f_ret,shell.f_done); //post cond: f_ret=2*2 f_done=false
...
f(f_coro,f_locals,shell.f_ret,shell.f_done); //post cond: f_ret=0 f_done=trueTip
- void f(T* px) === void f(T& x)
- Stackless => No recursion!
Turn in
- You shall implement the long computation task as a stackless coroutine using the given APIs.
- Add a new menu item/builtin command for calling it.
Check
- On key press, the status bar shall be updated with ‘the number of keys pressed so far’ while the long computation task is running(not after it finishes).
- Result of both the menu items should be same.
Note
- You’re required to initialize the coroutine from shell_step_coroutine(). You may have a statemachine (DEAD,START,READY), and on state transition from DEAD->START, you may want to initialize the coroutine.
Note
- Have you noticed that we need to save value of local variables in a structure and that stack is not preserved? In the next part, we’ll implement a stack for each coroutines, and let local variables stored on stack instead of new structure.
2.2 Fiber
MergeRequest
I’ve added few more code in origin/fiber branch. Please merge it with your master branch
user@host:~/hohlabs$ git pull
user@host:~/hohlabs$ git merge origin/fiberAim
In this part, we’ll learn about “fibers” while enhancing our kernel to make it responsive to key presses while long computation task is running.
- You shall implement the long computation task as a fiber using the given APIs and add a new menu item/builtin command for the same.
- On key press, the status bar shall be updated with ‘the number of keys pressed so far’ while this long computation task is running(not after it finishes).
- Result of all three menu items should be same.
- Atmost one pending long computation task at any point in time.
- Only convert one long computation task to fiber form(If your shell supports multiple long computation task).
Information
Usage
core_loop_step():
if user has pressed key, get the key and do:
shell_update(ro: key, rw: shell_state);
// execute shell for one time slot to do some computation, if required.
shell_step(rw: shell_state);
// execute shell for one time slot to do some computation, if required.
shell_step_coroutine(rw: shell_state, rw: f_coro, rw: f_locals);
// execute shell for one time slot to do some computation based on fiber, if required.
shell_step_fiber(rw: shell_state, rw: main_stack, rw: f_stack, rw: f_array, ro: f_arraysize);
// shellstate -> renderstate: compute render state from shell state
shell_render(ro: shell_state, wo: render_state);
if not render_eq(last renderstate and new renderstate):
render(ro: render_state, wo: vga text buffer);Define
You need to define the following functions in labs/fiber.cc
shell_step_fiber(shellstate_t&, addr_t& main_stack, addr_t& f_stack, addr_t f_array, uint32_t f_arraysize);You also need to enhance your shell implementation in labs/shell.h
update shellstate_t and renderstate_t structure:
for handling fiber state, and
new menu item for long computation task as fibersYou also need to enhance your shell implementation in labs/shell.cc
new menu item for long computation taskGiven
stack_reset(f_stack,f_array,f_arraysize,f_start,f_args...) : resets the stack. use std::ref() from functional to pass references
stack_resetN(f_stack,f_array,f_arraysize,f_start,f_args...): resets the stack. for C/ older C++ compilers.
stack_saverestore(from_stack,to_stack) : saves the context to from_stack, restore the context from to_stack.Example usage of fibers
void f(addr_t* pmain_stack, addr_t* pf_stack, int* pret, bool* pdone){
addr_t& main_stack = *pmain_stack; // boilerplate: to ease the transition from existing code
addr_t& f_stack = *pf_stack;
int& ret = *pret;
bool& done = *pdone;
int i;
int j;
for(i=1;i<=3;i++){
for(j=1;j<=3;j++){
ret=i*j;done=false; stack_saverestore(f_stack,main_stack);
}
}
for(;;){
ret=0;done=true; stack_saverestore(f_stack,main_stack);
}
}
// How to use use f()?
uint8_t f_array[F_STACKSIZE];
const size_t f_arraysize=F_STACKSIZE;
addr_t main_stack;
addr_t f_stack;
stack_reset4(f_stack, &f_array, f_arraysize, &f, &main_stack, &f_stack, &shell.f_ret, &shell.f_done);
stack_saverestore(main_stack,f_stack); //post cond: f_ret=1*1 f_done=false
stack_saverestore(main_stack,f_stack); //post cond: f_ret=1*2 f_done=false
stack_saverestore(main_stack,f_stack); //post cond: f_ret=1*3 f_done=false
stack_saverestore(main_stack,f_stack); //post cond: f_ret=2*1 f_done=false
stack_saverestore(main_stack,f_stack); //post cond: f_ret=2*2 f_done=false
...
stack_saverestore(main_stack,f_stack); //post cond: f_ret=0 f_done=true
Extra information
//
// Switch stacks.
//
// Algo:
// 1. Save _c's context to stack,
// 2. push ip of _c's restore handler
// 3. switch stacks
// 4. execute ip of _n's restore handler to restore _n's context from stack.
//
//
// stack layout:
// teip[-1:-32]: continuation to restore,
// Stack layout expected by teip:
// ebp[ -33: -64],
// ebx[ -65: -96],
// eax[ -97:-128],
// Stack layout expected by eip+4:
// Preserved.
#define stack_saverestore(from_stack,to_stack) do { \
asm volatile( \
" pushl %%eax \n\t" \
" pushl %%ecx \n\t" \
" pushl %%ebp \n\t" \
" pushl $1f \n\t" \
" \n\t" \
" movl %%esp,(%0) \n\t" \
" movl (%1),%%esp \n\t" \
" \n\t" \
" ret \n\t" \
"1: \n\t" \
" popl %%ebp \n\t" \
" popl %%ecx \n\t" \
" popl %%eax \n\t" \
: \
:"a" (&from_stack), "c" (&to_stack) \
:_ALL_REGISTERS, "memory" \
); \
} while(false)
//
// Initializes stack.
//
// Algo:
// 1. Push Ip of reset handler
// (which will reset ebp and jmp to actual eip etc)
//
// stack layout:
// teip[-1:-32]: continuation to restore(1f),
// Stack layout expected by teip:
// args passed in registers when calling eip (NONE),
// eip[-33:-64],
// args passed in stack when calling eip (NONE),
//
// initial values: teip=t_start; eip=f_start;
//
#define stack_inithelper(_teip) do{ \
asm volatile( \
" movl $1f,%0 \n\t" \
" jmp 2f \n\t" \
"1: \n\t" \
" movl $0, %%ebp \n\t" \
" jmp *(%%esp) \n\t" \
"2: \n\t" \
:"=m" (_teip) \
: \
); \
}while(false)
Tip
NA
Turn in
- You shall implement the long computation task as a fiber using the given APIs.
- Add a new menu item/builtin command for calling it.
Check
- On key press, the status bar shall be updated with ‘the number of keys pressed so far’ while the long computation task is running(not after it finishes).
- Result of all the three menu items should be same.
Note
- To achieve responsiveness, we’ve to add yield points explicitly. Sometimes, it may not be easy - can we trade efficiency and implment pre-emptive scheduling? Yes, But Pre-emption requires support for timers. To use timers, we need to have support for interrupts. which means we need to write interrupt handlers and program Interrupt Descriptor Tables(IDTs)
Before we do so, let’s first implement support for multiple non-premptive threads.
Syntax: GCC Extended Asm
asm [volatile] ( AssemblerTemplate : OutputOperands [ : InputOperands [ : Clobbers ] ])Label 1f means: the immediate label 1 in the forward direction.. and label 1b means the immediate label 1 in the backward direction.. And $1f means address of label 1 in the forward direction.
In stack_inithelper macro, the _teip gets the address of label 1f.
:“a”(value) inside input operands means : gcc will make sure %eax is not live at that point, and Move the value into “%eax” register
:“c”(value) inside input operands means : gcc will make sure %eax is not live at that point, and Move the value into “%ecx” register
if a register is mentioned in clobbered list - gcc will ensure that register is not live before calling asm statement. (all the integer registers which are not pushed in the macro are mentioned in _ALL_REGISTERS as clobbered. stack_saverestore is a macro - not a function so no calling convention is applied)
Demo Tip
- On stack_savestore
- stack_initN pushes variable number of arguments (stack_init0 pushes 2, stack_init1 pushes 3)
- and stack_saverestore pops fixed number of arguments.
- How is it possible?
- Why are we saving only eax, ecx and ebp? Won’t the other registers get trashed by the fiber function (after executing stack_saverestore)?
2.3 Non-preemptive scheduling
MergeRequest
I’ve added few more code in origin/fiber_scheduler branch. Please merge it with your master branch
user@host:~/hohlabs$ git pull
user@host:~/hohlabs$ git merge origin/fiber_schedulerAim
In this part, we’ll learn about non-preemptive sheduling while enhancing our shell to support multiple pending long computation task.
- You will need to support at least two additional long computation tasks. Now that you have implemented fibers, your computational tasks could involve the use of stack. For example, you can implement a recursive implementation of the fibonacci series computation, which has exponential complexity.
- For these additional long computation tasks:
- You shall support multiple pending long computation tasks
- Add menu item/builtin command for calling additonal tasks(Retain previous menu items).
- Same command/menu item may be entered multiple times
- Each command may be queued at max 3 times.
- Total number of fibers in progress shall be limited to minimum of (5 or stacks_size or arrays_size). Note: only additional long computation tasks are counted
Information
NA
Usage
core_loop_step():
if user has pressed key, get the key and do:
shell_update(ro: key, rw: shell_state);
// execute shell for one time slot to do some computation, if required.
shell_step(rw: shell_state);
// execute shell for one time slot to do the computation based on coroutine, if required.
shell_step_coroutine(rw: shell_state, rw: f_coro, rw: f_locals);
// execute shell for one time slot to do the computation based on fiber, if required.
shell_step_fiber(rw: shell_state, rw: main_stack, rw: f_stack, rw: f_array, ro: f_arraysize);
// execute shell for one time slot for additional long computation tasks.
shell_step_fiber_scheduler(rw: shell_state, rw: stackptrs, ro: stackptrs_size, rw: arrays, ro: arrays_size);
// shellstate -> renderstate: compute render state from shell state
shell_render(ro: shell_state, wo: render_state);
if not render_eq(last renderstate and new renderstate):
render(ro: render_state, wo: vga text buffer);Define
You need to define the following functions in labs/fiber_scheduler.cc
shell_step_fiber_scheduler(shellstate_t&, addr_t stacks[], uint32_t stacks_size, addr_t arrays, uint32_t arrays_size);You also need to enhance your shell implementation in labs/shell.h
update shellstate_t and renderstate_t structure:
for handling scheduler state, etcYou also need to enhance your shell implementation in labs/shell.cc
atleast two long computation tasks.
and ui changes.etcGiven
NA
Tip
This is the goal: So far, we have the capability to run only one fiber. We need to support multiple fibers - Let's say:G and H with types:
1. G:: GArg -> GResult
2. H.:: HArg -> HResult
We also want to support multiple invocations of these fibers. (atmax 3). Question also states about one more constraint - total number of instances for G and H should be <= 5.
Now, we have to store 3*(GArg,GResult) and 3*(HArg,HResult) in shellstate_t.. just like we did it for f (we'd stored args and result in shellstate for 1.5 and 1.6).
What should be a good data structure for storing these? Two common approaches are:
1. 3*(GArg,GResult) and 3*(HArg,HResult)
2. 5* Union of (GArg,GResult) and (HArg,HResult)
How to do scheduling?
Let's say, we have a circular buffer/linked list on top of array.
When someone wanted to start an instance(press enter), just check the resource limitations. and change state, add into the queue.
and in each invocation of fiber_scheduler... just pick one fiber(round robin), and execute.
ie. in next invocation - pick the next fiber and execute it.. so on.
This is just one way to implement.. You don't need to implement this way
- mentioned at the last day to help those students who're running out of
time.Turn in
- You shall support multiple pending long computation tasks
- Add few more menu item/builtin command for calling it.
Check
Note
Optional Design check
To test how good is your design:
- commenting out shell_step_fiber:
- is it equivalent to take fiber computation taking infinite amount of time
- commenting out shell_step_coroutine():
- is it equivalent to take coroutine computation taking infinite amount of time
etc.
2.4 Preemption (threads)
MergeRequest
I’ve added few more code in origin/preemption branch. Please merge it with your master branch
user@host:~/hohlabs$ git pull
user@host:~/hohlabs$ git merge origin/preemptionAim
In this part, we’ll learn about “preemption” while enhancing our kernel to make it responsive to key presses while long computation task is running.
- You shall enhance the fiber implementation by adding preemption.
- You need to write a part of trap handler - ring0_preempt - which should switch stack to ‘main_stack’
- We would like to reuse shell_step_fiber_scheduler to do the scheduling.
- You shall program one-shot LAPIC timer to raise an interrupt after a specified time.
- For simplicity, we’ll go with dynamic timers
- If there’s no fibers running, there shouldn’t be any timers firing.
- You shall also take care of the data race, if any, between the ring0_preempt and fiber’s explicit yields
- Threads can be explicitly yielded using stack_saverestore(non preemptive context switch), or can be preempted by ring0_preempt from our timer’s trap handler.
- Floats and SIMDs(SSE) instructions are allowed in our kernel. ring0_preempt macro shall save and restore FPU/SIMD registers (context) as well during the context switch.
- Out of two additional fibers implemented during fiber_scheduler:
- One of the fiber should be running normally with non-preemptive yields (stack_saverestore) (This is to trigger race condition between yield and ring0_preempt) and
- another fiber shall be modified to execute without yields in between the computation (This is to check preemption is working or not)
- Those who havnt done fiber_scheduler part can show preemption with fiber part
- They need to show preemption with and without yields in the fibers.
You also have to make following changes in the existing implementation:
- Fix the types of shell_step_fiber and shell_step_fiber_scheduler functions in labs/fiber.{h,cc} and labs/fiber_scheduler.{h,cc}
- shell_step_fiber and shell_step_fiber_scheduler are now passed extra arguments - timer device and a preempt_t structure.
- You’ve to modify types of these functions to fix the compiler/linker error
- Update shell_step_fiber_scheduler to use main_stack.
- shell_step_fiber_scheduler is now passed main_stack as an argument
Information
- Lecture videos:
FXSAVE and FXRSTOR assembly instructions: To save and restore FPU/SIMD registers To save/restore all these registers, Intel provided a single instruction FXSAVE/FXRSTOR.
To know more about fxsave and fxrstor instruction, please read: Vol-1, Chapter 10, Section 5. You can use the example on Page 404 (Section E.2, Example E-1) for the code required to save and restore these registers. Notice that you need to create a space for 512 bytes, aligned at a 16-byte boundary to be able to execute the FXSAVE instruction.
Note that memory address passed to fxsave and fxrstor must be 16 byte aligned. ie. must be a multiple of 16.
Possible Control flow
Make sure your ring0_prempt will be able to work with below scenario
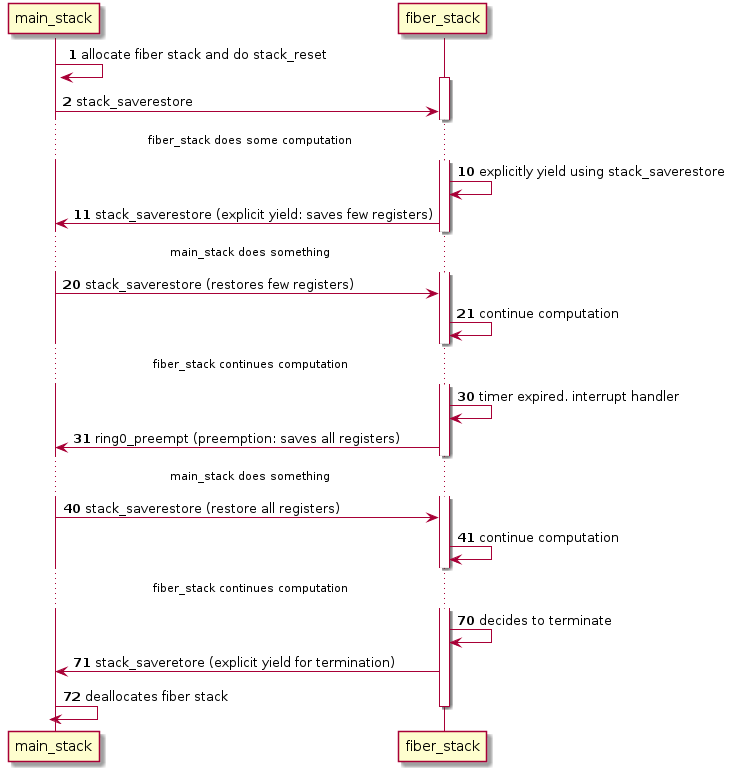
Main thread (fiber scheduler) : The main thread needs to distinguish between the two cases: one where the control reached it due to voluntary switching from a fiber thread (through calling stack_saverestore directly) [step 11 in figure], and the other where the control reached it due to preemption [step 31 in figure]. For the first case, the location of the stack pointer of the switched-out fiber is available in the parameter “from_stack” of stack_saverestore. For the second case, the pointer would be available in the core_t.preeempt.foo field (implemented by you).
FPU: eax,ecx, edx, ebx, esp, ebp, esi, edi are all integer registers.
Let’s try to write a simple C functions which add two floats:
float add(float a, float b){ return a+b; }Which registers are they going to use, and which instructions? integers registers? addl instruction? No! What’s the format of floats? number is represented as (sign,mantisa,exponent). To know about it, please read about IEEE754 floating point representation/basic computer architecture course. That’s where legacy 8087 FPU comes into picture.
It has 8 80-bit FPU registers: st(0),st(1), st(2)…st(7). ( 1 bit sign, 64 bit mantissa, 15 bit exponent) sizeof(double)=8. Floating point loads and stores will convert this 80-bit representation to 64 bit representation when it store to memory.. and viceversa. To know about FPU registers, please read: Vol-1, Chapter 8
MMX/SIMD2: With one instruction, we want to add N pairs in parallel, which means we want registers than hold N ints (or N floats).
x86 has mm0, mm1, mm2.. mm7 (which are SIMD2, ie. N=2 - it holds two floats). To know more about MMx registers, please read: Vol-1 Chapter 9
SSE/SIMD4: It also introduced SIMD4(128 bit registers) xmm registers. xmm0, xmm1 … xmm7. To know more about xmm registers, please read: Vol-1 Chapter 10
AVX/SIMD8 Intel also introduced (SIMD8) ymm registers in architectures like Sandybridge, Haswell etc. but since our gcl machines doesn’t support these - we won’t discuss it here.
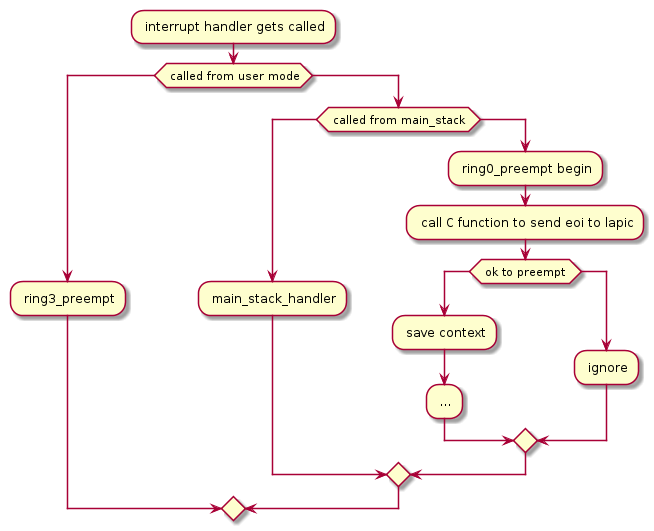
Overview of preemption handler’s control flow:
Usage
Read the code - to understand where ring0_prempt is getting called
Define
You need to define the following structures in labs/preempt.h
// preempt_t : State for your timer/preemption handler
struct preempt_t{
};You also need to define the following functions in labs/preempt.h
//
// _name: label name
// _f : C function to be called
//
# define _ring0_preempt(_name,_f) \You also need to modify labs/fiber.cc and labs/fiber_scheduler.cc to set the timer and reset the timer
Given
- lapic.reset_timer_count(N); to generate a timer interrupt after N timer ticks (N=0 to stop)
Both the shell_step_fiber and shell_step_fiber_sched are passed an dev_lapic_t object. which has a member function:
reset_timer_count(int count).LAPIC Timer unit will decrement this count every tick, and when it reaches zero, will fire a timer interrupt.
To know more about LAPIC Timer: please read: Vol 3A, 10.5.4.
- Our kernel does not have any global variables, and our trap handler is stateless. So we map our state to %gs. ie. %gs:0 will point to zeroth byte of core_t structure. %gs:1 will point to first byte.. so on (Read the code for more info).
Tip
- Make sure you understand the stack_saverestore(util/fiber.h) function you used in 1.6 and 1.7 parts.
%gs: See x86/main.h and x86/except.* on usage of %gs
Outline of ring0_preempt:
#define _ring0_preempt(_name,_f)
_name:
call C function: _f
// begin
if thread is already inside yield,
jmp iret_toring0
save the CPU state to current stack (fiber's stack)
save the current stack pointer to core_t.preempt.foo
switch context and stack using stack_saverestore()
... (control will not reach here immediately, it will reach here only on the next context switch back to this fiber)
restore CPU state from the current stack
jmp iret_toring0Hints
- The arguments of stack_saverestore (from_stack and to_stack) need to be obtained from %gs
- On returning from stack_saverestore(), the main thread should check if the switched-out thread was preempted; if so, it may want to update the corresponding fiber’s stack pointer (using core_t.preempt.foo). Also, you want to re-enable interrupts (using sti), after returning from stack_saverestore()
- To deal with the race-condition, where an interrupt can occur during a voluntary yield, you may want to implement a flag in preempt_t, that is set before starting voluntary yield, and is cleared by the main thread. Recall that a timer interrupt can only occur while the CPU is running a fiber (or is context-switching back to main) — we use a one-shot LAPIC timer, not a periodic timer.
Turn in
Check
- On key press, the status bar shall be updated with ‘the number of keys pressed so far’ while the long computation task is running(not after it finishes).
- Result of all the three menu items should be same.
- On demand timer ticks: No timer ticks if there’re no fibers running.
Note
NA